

 Andreas Johnsen
Andreas Johnsen
Dette er en ekspertartikel, alternativt kan du læse den ikke tekniske version her. Artiklen har til hensigt at skitsere, hvordan arkitekturen inden for dataplatforme har udviklet sig over tid. Artiklen giver også et bud på, hvilken platform der bedst understøtter de udfordringer og muligheder, virksomheder står overfor i dag, hvor der er særligt fokus på chatbots, Agentic AI og live-streaming.
Først fokuserer jeg på, hvorfor et Data Lakehouse er det rette valg, når AI og live-streaming spiller en central rolle i virksomheders udvikling. Dernæst tydeliggøres det, hvordan arkitekturen ser ud i et universelt Data Lakehouse. Jeg gennemgår:
- Data storage
- Data ingestion
- Compute layer
- Data governance
Afslutningsvis beskriver jeg, hvordan strategiske tiltag kan hjælpe virksomheder bedst i gang med at etablere eller migrere til et Data Lakehouse.

Skrevet d. 01-04-2025 af Andreas Johnsen, Seniorkonsulent hos itm8
Baggrund
Mens AI er blevet en fast del af vores hverdag, kæmper virksomheder med at migrere deres nuværende dataplatforme til mere moderne dataplatforme, der understøtter en robust, fleksibel og konsolideret arkitektur. Dette er afgørende for at realisere det potentiale, AI muliggør.
Data Lakehouse-arkitekturen har vundet indpas hos et stigende antal virksomheder, da den samler og optimerer datahåndteringen ved at kombinere forskellige datakilder og platforme i en strømlinet og moderne løsning.
Derfor kombineres det traditionelle Data Warehouse med Data Lake, hvilket understøtter alle datadiscipliner, herunder:
- Rapportering
- Data engineering
- Machine learning
- Real time streaming
- BI
- AI
- Chatbots og Agentic AI
Denne arkitektur er fleksibel, har en solid governance-struktur og indebærer ingen "vendor lock-in". Det betyder, at virksomheder kan sammensætte deres Data Lakehouse-løsning med teknologier fra forskellige cloudleverandører.
Et paradigmeskifte fra Data Warehouse og Data Lake til én samlet løsning: Data Lakehouse
Data Warehouse
I årtier har Data Warehouse været den foretrukne dataplatform for virksomheder, der anvender Business Intelligence og rapportering. Denne arkitektur er optimeret til strukturerede data og har høj ydeevne.
Dog har den eksponentielle vækst i datamængder og AI's stigende betydning udfordret Data Warehouse-modellen. AI kræver ofte store mængder strukturerede og ustrukturerede data, som et traditionelt Data Warehouse kan have svært ved at håndtere. Samtidig kan de stigende datamængder medføre høje omkostninger til serverkapacitet og vedligeholdelse.
Data Lake
Data Lake vandt indpas i 2010'erne, da det var skræddersyet til lagring af store mængder ustrukturerede data til en lav pris. Arkitekturen er velegnet til AI og store datamængder, men har begrænsninger, da den mangler robust governance, datasikkerhed og ACID-egenskaber (Atomicity, Consistency, Isolation og Durability).
Data Lakehouse
Et Data Lakehouse kombinerer fordelene ved Data Warehouse og Data Lake. Det betyder, at virksomheder kan anvende en enkelt platform til både nuværende og fremtidige datadiscipliner.
De primære fordele ved et Data Lakehouse er:
- Billig datalagring af alle typer data
- Robust data governance
- Anvendelse af åbne dataformater
- Understøttelse af alle data discipliner så som; Generativ AI og LLM’s.
- Næsten ubegrænset mulighed for opskalering af datalagring og compute power
- Konsolidering af data siloer til en samlet platform
- Nedbringelse af virksomheders tekniske gæld
- Afkobling mellem datalagring og ”compute layer”, hvilket øger performance.
Hvordan ser Data Lakehouse arkitekturen ud?
I denne sektion gennemgår vi de vigtigste komponenter i et Data Lakehouse:
- Data ingestion: Processen, hvor data hentes fra forskellige kilder og overføres til Data Lakehouse-lagring.
- Data storage: Opdelingen af lagring i Cloud Storage, åbne filformater og tabelformater.
- Compute layer: Muligheden for fleksibel opskalering af compute power og separation fra lagring.
- Workloads:De forskellige datadiscipliner, Data Lakehouse understøtter, herunder BI, AI, streaming og rapportering
- Data governance: Administrering af metadata, adgangskontrol, sikkerhed og compliance.

Data Ingestion
Denne komponent anvendes til at hente data fra datakilder og overføre disse ned i Data Lakehouse data storage. Denne overførsel af data kan være:
- Batch (pull or push)
- Real time
- Streaming
Data Lakehouse har mulighed for at anvende et specifikt data ingestion værktøj, eksempelvis Azure data factory, IBM streamsets og Databricks eller udvikle egen data ingestion programmer via API’er og python.
Data Storage
Først opdeles datalagring i tre områder. Derefter viser vi, hvordan data storage-arkitekturen (The Medallion Architecture) strukturerer kildedata og øger kvaliteten, så data bliver klar til forretningen.
Datalagring
Nedenstående figur viser opdelingen af begrebet datalagring i tre kategorier:
- Cloud storage
- Åben filformat
- Åben tabelformat
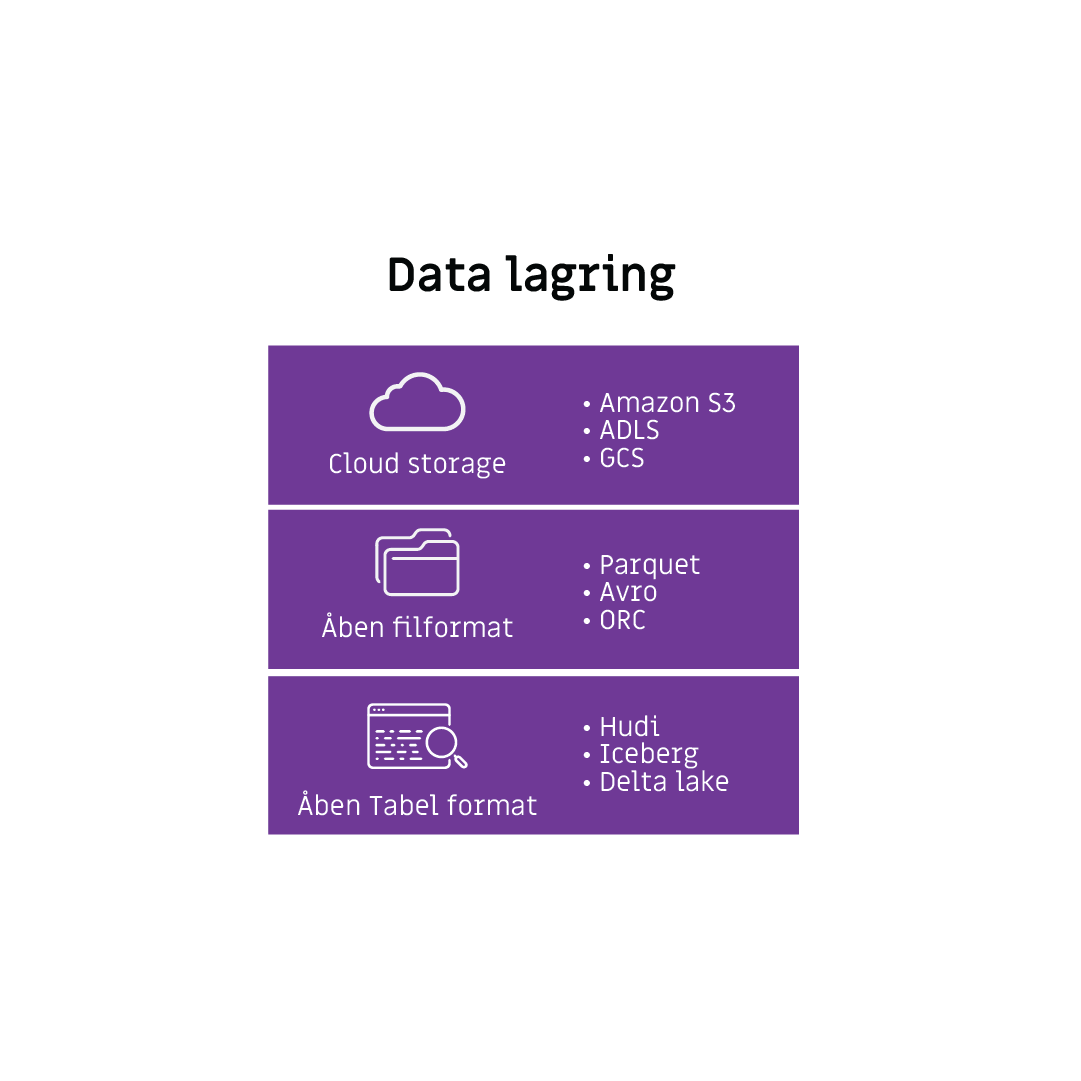
Cloud storage kan bestå af diverse cloudleverandørers cloud storage så som:
- Azure – Azure data lake storage Gen2 (ADLS)
- Amazon – Simple storage service (S3)
- IBM – Cloud object storage (COS)
- Google – Google cloud storage (GCS)
- Oracle – Oracle cloud infrastructure (OCI)
Data som er lagret i Data Lakehouse understøtter åbne filer og tabelformater
Eksempler på åbne filer og tabelformater
Åbent tabelformat
Et åbent tabelformat fungerer som en slags organiseret indpakning omkring dine data i en tabel. Hvis en tabel anvender åbent tabelformat, vil indpakningen bestå af en række filer som har til hensigt at:
- Følge skemaændringer på tabellen
- Følge tabellens datafiler og dens kolonners statistik.
- Følge indsættelse/opdatering/sletning på tabellen
Filerne som holder informationen om den pågældende tabel giver mulighed for at anvende nedenstående:
- Time travel på tabellen
- Tabellen kan opdeles i sektioner uden at genloade data
- Håndtering af læsning og skrivning på tabellen på samme tid
Åbne tabelformater kan være:
- Apache Iceberg
- Apache Hudi
- Delta lake
Åbent filformat:
Som ordet ”åbent” antyder, er dette filformat ikke et proprietærformat. Et proprietærformat er et lukket fil- eller dataformat, som kun fungerer med en bestemt software, platform eller leverandør.
Det åbne filformat betyder, at data kan blive lagret, tilgået og anvendt af forskellige dataplatforme og software applikationer. Det giver yderligere virksomhedens brugere, såsom Data engineers, Business analysts eller data scientists mulighed for at tilgå data via deres fortrukne værktøj.
Åbne filformater er bl.a:
- CSV
- JSON
- XML
- Parquet
- ORC
- Avro
Desuden omfavner Data Lakehouse alle datatyper:
- Struktureret data
- Semistruktureret data
- Ustruktureret data
The medallion archicture

Denne arkitektur har til formål at strukturere og forbedre datakvaliteten via dataflytning mellem tre lag:
- Bronze
- Sølv
- Guld
Bronze:
Dette lag er landingszone for alt data, der kommer ind fra eksterne datakilder og bør være et spejl af data, som det ser ud i kildesystemerne. Dataene kan have supplerende datakolonner når det er havnet i bronzelaget, f.eks. metadatakolonner. Derudover fokuseres der i bronzelaget på at få opbygget historik via “change data capture” og data lineage.
Sølv:
I dette lag bliver data renset. Det indebærer identificering og rettelse af fejl, inkonsistens i data eller uhensigtsmæssigheder i data. Disse tiltag bliver gjort for at øge pålideligheden og kvaliteten af data.
Konkret kan det være:
- Fjernelse af dubletter
- Standardiserer dataformater
- Håndtering af ”null values”
Guld:
I det sidste lag skal data være klar til at blive anvendt af diverse stakeholders i virksomheden.
Derfor bliver følgende gjort ved data i guld-laget:
- Forretningslogikken indlejres
- Data aggregeres/samles
- De relevante tabeller, hvor data ligger, bliver performance optimeret
- Data modellering over de efterspurgte tabeller.
Compute Layer
Data Lakehouse er open source, hvilket giver virksomheder mulighed for at anvende forskellige cloudleverandører og deres tilhørende “pompute engines”
”Compute layeret” anvendes, når der skal udvikles inden for ETL, BI, AI eller software applikationer.
Et Data Lakehouse har typisk adskillige compute enginees, som bruges til de forskellige områder.
Disse compute engines kan have forskellige størrelser af CPU og Memory. I modsætning til en database, hvor forskellige brugere kæmper om CPU og memory, når de anvender databasen, kan brugere i Data Lakehouse have adskillige compute engines kørenede på samme tid, uden at de forstyrrer hinandens arbejdsgange.
Disse compute engines kan hurtig oprettes og konfigureres efter behov. Samtidig betaler man først, når man tænder for den, og man kan konfigurere sine clusters til at slukke efter X antal minutter, når det ikke længere anvendes.
Workloads
Denne komponent dækker over de forskellige dataområder, som Data Lakehouse understøtter. Dette inkluderer:
- BI
- Rapportering
- Data science (AI)
- Machine learning
- Real-time streaming
- Chatbots og Agentic A
Data Governance
Data Governance
Data Lakehouse kan understøtte alle føromtalte områder, på grund af et koncept kaldet: ”Unified data catalogue”.
Denne term dækker over, hvordan Data Lakehouse administrer:
- Metadata
- Adgangskontrol
- Data governance
- Data lineage
- Sikkerhed
- Datadeling
- Auditing
- Monitorering
- Håndtering af PII data
Data Lakehouse: arkitekturen udvikler sig konstant
Lige nu er Data Lakehouse den optimale arkitektur, men behovet for nye løsninger vil altid udvikle sig, fordi:
1. Dagens "ways of working" ikke nødvendigvis er morgendagens. Datamængder og hastigheden af dataomsætning udvikler sig konstant.
2. Teknologien udvikler sig i et stadig højere tempo. Det øger organisationers datamodenhed, reducerer infrastrukturpriser og gør det lettere at finde kvalificeret arbejdskraft.
For at sikre en fremtidssikret arkitektur bør man altid spørge sig selv:
- Hvor let er platformen at komme i gang med?
- Kan platformen understøtte både nuværende og fremtidige behov?
I dag er Data Lakehouse svaret på begge spørgsmål.
Hvilke overvejelser er vigtige, inden man migrerer til Data Lakehouse?
Inden virksomheder implementerer en ny platform, er det nødvendigt at forstå deres nuværende platform og hvilke krav både virksomheden og stakeholders har.
Nedenstående figur viser 3 nøgleområder, man bør være opmærksom på, før man migrerer til Data Lakehouse

Data platformens krav
- Platformen skal kunne håndtere AI/ML, BI, real-time streaming, ETL og datadeling.
- Den skal være fremtidssikret, fleksibel og kunne understøtte nye kildesystemer.
- Skal være sikker, compliant og omkostningseffektiv.
Forståelse af den nuværende dataplatform
- On-premise Data Warehouse kan være svære at skalere
- Performanceproblemer ved BI-dashboards
- Manglende understøttelse af AI/ML og datadeling.
- Udfordringer med adgangsstyring
For at komme overstående problemstillinger til livs, er det vigtigt at snakke med forskellige interessenter for at danne en komplet oversigt og kende virksomhedens: ”pains and gains”
Forstå organisations visioner og data strategi
De fleste virksomheder har visioner om at blive ”data-driven” og vil demokratisere data. Virksomheder med disse visioner har oftest en strategi til, hvordan det skal gøres. Her oplistes de mest hyppige indikatorer en datastrategi fokuserer på:
- Nedbrydning af datasiloer og demokratisering af data, for hurtigere at kunne træffe beslutninger
- Etablering af et robust datafundament
- Stærk data governance og pålideligt dataflow.
- Mål om at blive "best-in-class" inden for branchen
Foretag workshops og interviews
Den bedste måde at få indsigt i sin virksomheds udfordringer og potentiale er ved at snakke med forskellige interessenter. Det kan være:
- Ledere
- Løsningsarkitekter
- Udviklere
- Analytikere
- Forretningens brugere
- Eksterne partnere som Microsoft, Oracle, IBM, Databricks
At inddrage de rette interessenter er afgørende for at få et komplet billede af virksomhedens behov og udfordringer. Alt for ofte bliver beslutninger truffet uden at konsultere dem, der skal bruge løsningen i praksis, hvilket kan føre til ineffektive implementeringer og oversete udfordringer.
Er I klar til at udnytte potentialet i Data Lakehouse?
Hos itm8 har vi specialiseret os i en cloud-agnostisk tilgang til opbygning af et Data Lakehouse.
Det betyder, at vi tilbyder et Data Lakehouse funderet på den cloudteknologi der passer bedst til dit behov.
Dette kan være:
- Databricks
- AWS
- Azure
- Snowflake
- IBM
- Oracle
Så uanset hvilken cloudteknologi du benytter i dag, kan du få glæde af at migrere til Data Lakehouse.