

Data Lakehouse er en samlet dataplatformsløsning, der bygger på open source og fokuserer på alle datadiscipliner
Kunstig intelligens er måske allerede blevet en fast del af din hverdag. Men med øgede krav til datasikkerhed og massive mængder data, kæmper mange virksomheder med at balancere behovet for fleksibilitet og skalerbarhed. Drømmer du om at anvende fremtidige datadiscipliner og gøre brug af AI i din forretningsstrategi, der bygger på open source? Så kan det være en fordel at skifte til et Data Lakehouse.

Hvad er et Data Lakehouse?
Et Data Lakehouse er en samlet løsning, som konsoliderer Data Warehouse og Data Lake til én platform. Men hvad er forskellene egentlig? Og hvad er fordelene og ulemperne ved dem hver især?
Data Warehouse
Et traditionelt Data Warehouse tilbyder struktureret datastyring, men det kan ofte være en væsentlig dyrere og ufleksibel løsning.
Data Lake
En Data Lake tilgang giver en omkostningseffektiv datalagring, men kan derimod ofte mangle governance og performance.
Data Lakehouse
Et Data Lakehouse samler det bedste fra Data Warehouse og Data Lake til en samlet dataplatform, hvor der er fokus på datastyring, governance og alle datadiscipliner, så det er muligt at bruge AI aktivt i sin data- og forretningsstrategi.
8 fordele ved en Data Lakehouse-løsning
De primære fordele ved et Data Lakehouse er:
- Billig datalagring af alle typer data
- Robust data governance
- Anvendelse af åbne dataformater
- Understøttelse af alle data discipliner så som; Generativ AI og LLM’s.
- Næsten ubegrænset mulighed for opskalering af datalagring og compute power
- Konsolidering af data siloer til en samlet platform
- Nedbringelse af virksomhedens tekniske gæld.
- Afkobling mellem datalagring og ”compute layer”, hvilket øger performance.

Adskillelse af ydeevne og datalagring giver større fleksibilitet og skalerbarhed
Ved Data Lakehouse er ydeevne og datalagring adskilt. Tidligere har data og dataplatforme været afhængige af den underliggende lagringsinfrastruktur. Det betød, at hvis du skulle have mere ydeevne, måtte du også opgradere din lagring og omvendt.
Når ydeevne og datalagring er adskilt, får du en løsning, hvor du ikke er låst til én stor og dyr platform. Du får i stedet en fleksibel og skalerbar løsning, hvor du kun betaler for det du bruger.
Det giver følgende fordele:
- Billig datalagring:1 Terabyte pr/mdr. koster ca. 150 kr.
- Billige clusters: 14 GB Memory, 4 kerne pr/time koster ca. 25 kr.
- Adskillige clusters som ikke influerer på hinandens jobs og udvikling
- Næsten ubegrænset mulighed for opskalering af datalagring eller jeres clusters memory og kerner.
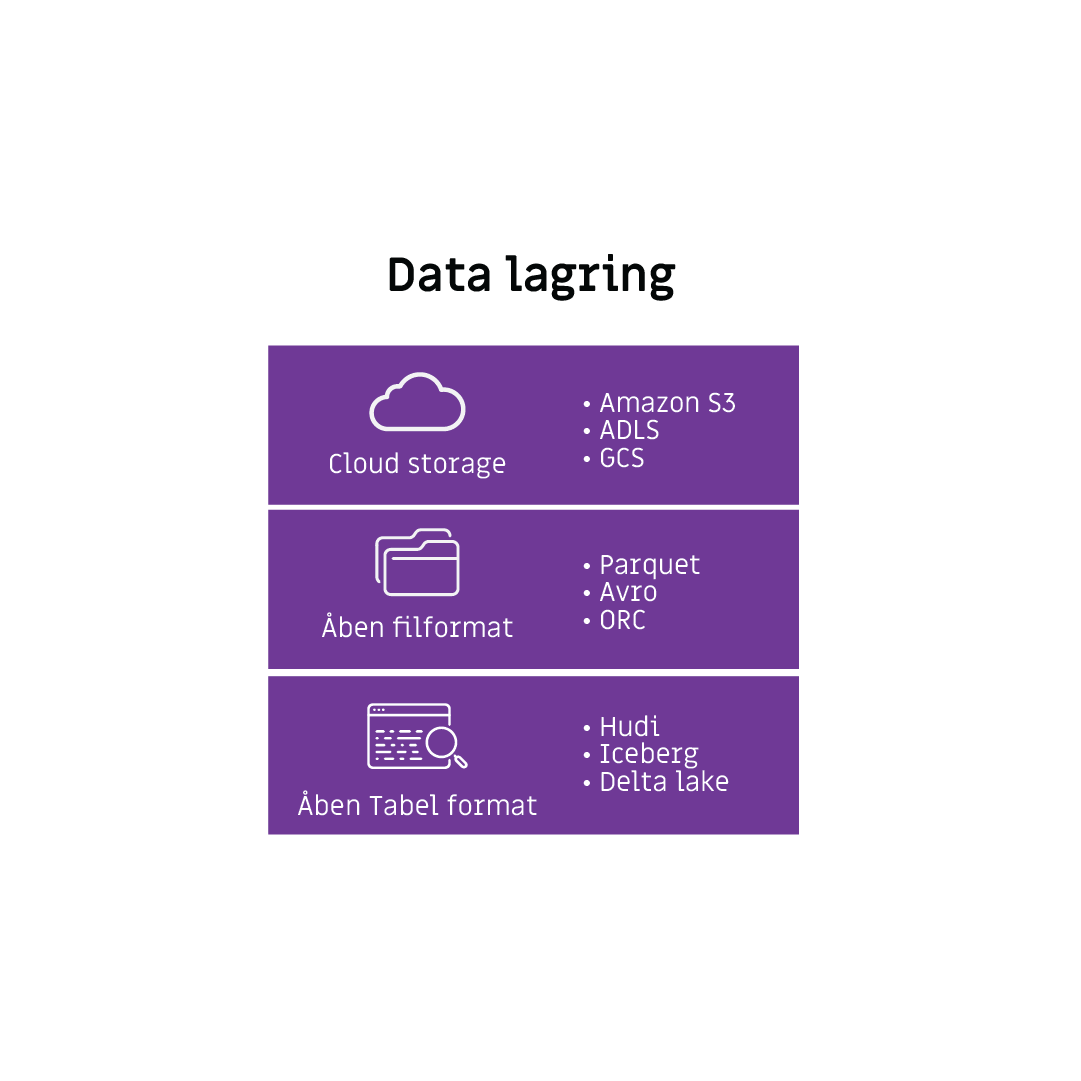
Et åbent og standardiseret format uden begrænsninger
Et Data Lakehouse anvender åbne og standardiserede formater. Det gør, at data kan bruges af mange forskellige systemer og programmeringssprog uden begrænsninger.
Derudover er programmeringssproget ikke låst til en bestemt softwareleverandør eller teknologi. Det betyder, at det er nemmere at arbejde med data på tværs af systemer og teknologier.
Det åbne format giver eksempelvis mulighed for at anvende disse forskellige programmeringssprog:
- Python
- =R
- Scala
- SQL
Derudover kan du anvende alle datatyper:
- Struktureret
- Semistruktureret
- Ustruktureret
Denne fleksibilitet i både datatyper og programmeringssprog gør, at data ikke blot kan lagres effektivt – det kan også anvendes i realtid. Når data er tilgængelige og anvender åbne formater, bliver det muligt at arbejde med avancerede teknologier som real-time streaming og AI direkte i lakehouse-arkitekturen
Data Lakehouse understøtter real-time streaming og AI
Et Data Lakehouse kan håndtere både store datamængder og realtidsbehandling, hvilket gør det ideelt til brug af:
- Internet of thing (IoT)
- Generativ AI
- Large language models (LLM)
- Agentic AI
- Fraud detection
Data Lakehouse er altså en oplagt platform til fremtidens datadrevne løsninger.

Hvordan kommer du i gang med et Data Lakehouse?
Før du kan komme i gang med at implementere et Data Lakehouse, ligger der et grundigt forarbejde. Den del vil vi selvfølgelig gerne hjælpe dig med.
Vores proces består først og fremmest i at få et indgående kendskab til din nuværende dataplatform. Ud fra dette kan vi gå videre med:
- Analyse af din nuværende dataarkitektur og identificering af forretningsmål
- Udarbejde en datastrategi i samarbejde med dig
- Design og implementering af et Data Lakehouse på baggrund af dine forretningskrav
- Automatisering af Lakehouse-opsætning via Infrastructure as Code (Terraform)
- Integration af AI og generativ AI for at maksimere værdien af dine data
Vil du gerne tage din dataplatform til næste niveau? Så lad os tage en snak om, hvordan et Data Lakehouse kan give din virksomhed nye muligheder, der passer til fremtidens datadiscipliner.
Hvorfor vælge os?
Vi er specialister i on-premises og cloudplatforme, som hjælper virksomheder med at implementere skræddersyede Data Lakehouse-løsninger. Vores tilgang sikrer, at din virksomhed får maksimalt værdi ud af jeres data.
- Vi er cloud-agnostiske i vores tilgang. Derfor kan vi hjælpe med at implementere jeres Data Lakehouse uanset hvilken Cloudleverandør du bruger. Vi har dyb viden om de forskellige cloudleverandører, såsom Databricks, Azure, IBM og AWS
- Vi kan implementere state-of-the-art AI og generativ AI-løsninger direkte i din dataplatform
- Vi laver et Data Lakehouse, der er skræddersyet til jeres behov og bygget på infrastructure as code.
Ofte stillede spørgsmål og svar
Tryk på spørgsmålet, for at få svaret.
-
Hvad er et Data Lakehouse?
Et Data Lakehouse er en moderne dataarkitektur, der kombinerer fordelene ved et Data Warehouse og en Data Lake. Det betyder, at virksomheder kan lagre og analysere alle typer data på én platform uden at skulle flytte data mellem forskellige systemer.
-
Hvordan adskiller et Data Lakehouse sig fra et Data Warehouse?
Et Data Warehouse er optimalt til struktureret data og BI-rapportering, men kan være dyrt at skalere og mindre fleksibelt. Et Data Lakehouse bevarer governance og ydeevne fra et Data Warehouse, men giver samtidig fleksibiliteten og skalerbarheden fra en Data Lake.
-
Hvordan adskiller et Data Lakehouse sig fra en Data Lake?
En Data Lake gør det nemt og billigt at opbevare store mængder data, men mangler ofte governance, sikkerhed og performance til analyser. Et Data Lakehouse tilføjer disse elementer, så virksomheder kan bruge deres data mere effektivt.
-
Hvad er fordelene ved et Data Lakehouse?
- Billig og fleksibel datalagring
- Stærk governance og datasikkerhed
- Understøtter både BI, real-time analyse og AI/ML
- Skalerbar og åben arkitektur uden vendor lock-in
- Konsoliderer datasiloer i én platform.
-
Hvilke virksomheder har brug for et Data Lakehouse?
Et Data Lakehouse er særligt relevant for virksomheder, der:
- Arbejder med store datamængder og har behov for hurtig adgang
- Udvikler AI og Machine Learning-modeller
- Ønsker real-time analyser
- Vil undgå vendor lock-in og drage fordel af åbne dataformater
-
Hvordan forbedrer et Data Lakehouse datastyring og governance?
Et Data Lakehouse har avancerede værktøjer til adgangskontrol, data lineage og overholdelse af compliance-krav. Det sikrer, at data er tilgængelig for de rette personer uden man går på kompromis med sikkerheden.
-
Understøtter et Data Lakehouse Generativ AI og Large Language Models (LLM’s)?
Ja, et Data Lakehouse er optimeret til AI-discipliner, herunder Generativ AI og LLM’s, da det kan håndtere både strukturerede og ustrukturerede data i store mængder.
-
Hvilke tekniske krav er der for at implementere et Data Lakehouse?
De tekniske krav afhænger af den valgte platform, men typisk kræves:
- Cloud- eller on-premise infrastruktur med skalerbar lagerkapacitet
- Understøttelse af åbne dataformater som Parquet og Delta Lake
- Værktøjer til dataintegration, AI og analyse
-
Hvad er de økonomiske fordele ved et Data Lakehouse?
Et Data Lakehouse reducerer omkostningerne ved datalagring og -behandling, da det understøtter skalerbare og fleksible løsninger. Virksomheder kan investere i præcis den kapacitet, de har brug for, uden at være låst til dyre proprietære løsninger.
-
Hvordan kommer man i gang med et Data Lakehouse?
Processen for at komme i gang med et Data Lakehouse ser cirka sådan ud:
- Analyse af jeres nuværende dataarkitektur og forretningsmål
- Udarbejdelse af en datastrategi
- Design og implementering af et Data Lakehouse baseret på jeres behov
- Automatisering af opsætning via Infrastructure as Code (Terraform)
- Integration af AI og Generativ AI for at maksimere forretningsværdien
